项目初始化
根据Flink Windows环境配置创建项目
项目实践
- 在
resources目录下创建wordcount.txt, 内容如下1
2
3
4a,a,a,a,a
b,b,b
c,c
d,d BatchJob实现对wordcount.txt内字母技术汇总1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
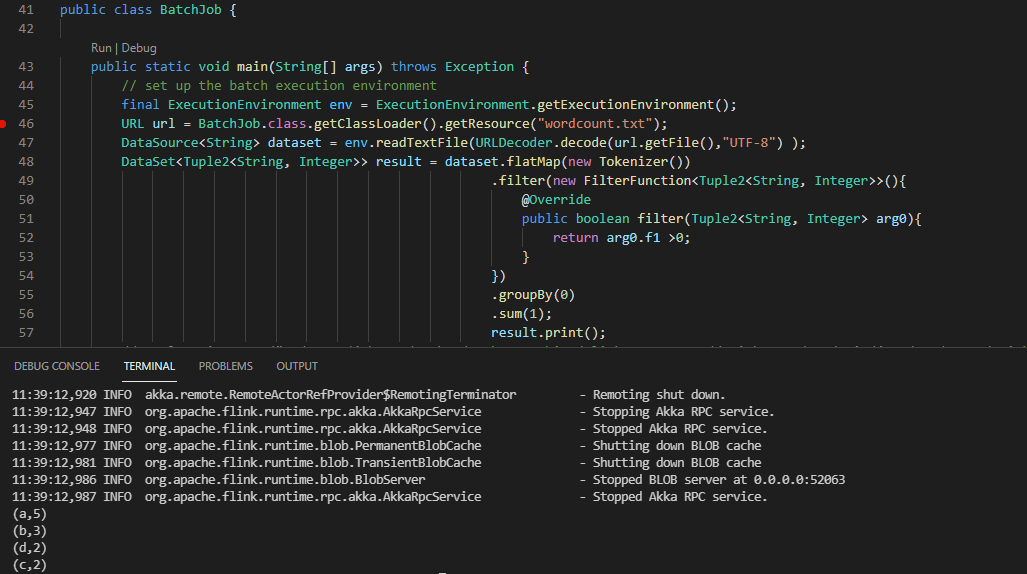
42package org.myorg.quickstart;
import java.net.URL;
import java.net.URLDecoder;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class BatchJob {
public static void main(String[] args) throws Exception {
// set up the batch execution environment
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
URL url = BatchJob.class.getClassLoader().getResource("wordcount.txt");
DataSource<String> dataset = env.readTextFile(URLDecoder.decode(url.getFile(),"UTF-8") );
DataSet<Tuple2<String, Integer>> result = dataset.flatMap(new Tokenizer())
.filter(new FilterFunction<Tuple2<String, Integer>>(){
@Override
public boolean filter(Tuple2<String, Integer> arg0){
return arg0.f1 >0;
}
})
.groupBy(0)
.sum(1);
result.print();
}
public static class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>>{
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] tokens = value.toLowerCase().split(",");
for (String token : tokens) {
if ( !token.isEmpty() && token.length() > 0) {
out.collect(new Tuple2<String, Integer>(token, 1));
}
}
}
}
}- 测试结果