配置启动Windows 10 Linux子系统
- 通过启用Windows 10 Linux子系统(WSL)安装配置WSL
下载安装Hadoop二进制文件
- 前往Hadoop发布页面找到需要下载版本的URL,这里下载最新的Hadoop 3.3.0
- 运行下面的命令下载安装
1
wget http://mirror.intergrid.com.au/apache/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
- 创建
hadoop文件夹保存解压后的hadoop 3.3.01
mkdir ~/hadoop
- 解压下载的Hadoop二进制文件
1
tar -xvzf hadoop-3.3.0.tar.gz -C ~/hadoop
- 进入hadoop文件夹
1
cd ~/hadoop/hadoop-3.3.0/
配置
passphraseless ssh - 检查是否可以通过
ssh到localhost1
ssh localhost
- 如果遇到错误
ssh: connect to host localhost port 22: Connection refused,尝试下面的命令1
2sudo apt-get install ssh
sudo service ssh restart - 如果无法无密码连接,运行下面的命令初始化私有和公有密钥
1
2
3ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
配置伪分布式模式(单节点模式)
- 通过修改
~/.bashrc配置系统环境变量1
vi ~/.bashrc
- 添加下面的环境变量
1
2
3
4export JAVA_HOME=/usr/lib/jvm/java-1.11.0-openjdk-amd64
export HADOOP_HOME=~/hadoop/hadoop-3.3.0
export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop - 运行下面的命令更新变量
1
source ~/.bashrc
- 修改
etc/hadoop/hadoop-env.sh1
vi etc/hadoop/hadoop-env.sh
- 设置
JAVA_HOME变量1
export JAVA_HOME=/usr/lib/jvm/java-1.11.0-openjdk-amd64
- 修改
etc/hadoop/core-site.xml1
vi etc/hadoop/core-site.xml
- 添加下面的配置
1
2
3
4
5
6<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration> - 修改
etc/hadoop/hdfs-site.xml1
vi etc/hadoop/hdfs-site.xml
- 添加配置
1
2
3
4
5
6<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration> - 修改
etc/hadoop/mapred-site.xml1
vi etc/hadoop/mapred-site.xml
- 添加配置
1
2
3
4
5
6
7
8
9
10<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration> - 修改
etc/hadoop/yarn-site.xml1
vi etc/hadoop/yarn-site.xml
- 添加配置
1
2
3
4
5
6
7
8
9
10<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>格式化
namenode1
bin/hdfs namenode -format
运行DFS程序
- 启动
NameNode和DataNode1
2
3
4
5hadoop@xx:~/hadoop/hadoop-3.3.0
$ sbin/start-dfs.sh
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [xx] - 检查状态
1
2
3
4
5hadoop@xx:~/hadoop/hadoop-3.3.0$ jps
4384 DataNode
4198 NameNode
4615 SecondaryNameNode
4766 Jps - 查看
name node
访问地址http://localhost:9870/dfshealth.html#tab-overview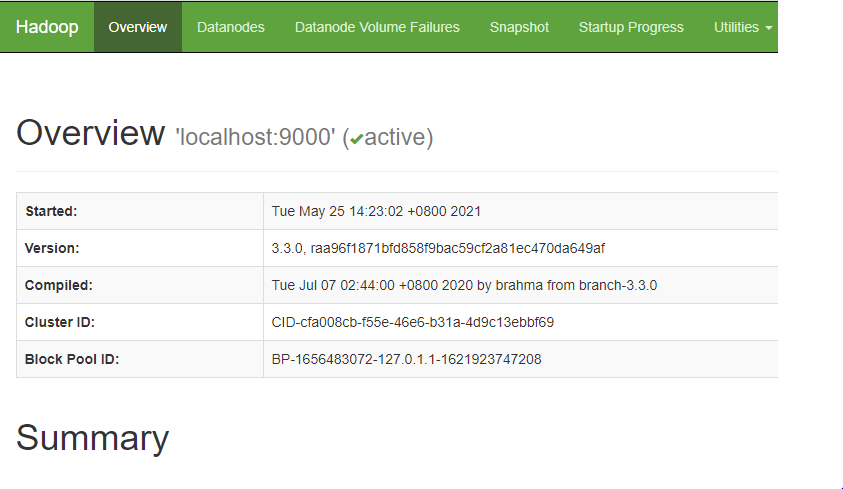
运行YARN
1 | sbin/start-yarn.sh |
– 检查状态
1 | hadoop@xx:~/hadoop/hadoop-3.3.0$ jps |
- 可以看到
NodeManager和ResourceManager - 访问
YARN地址http://localhost:8088/cluster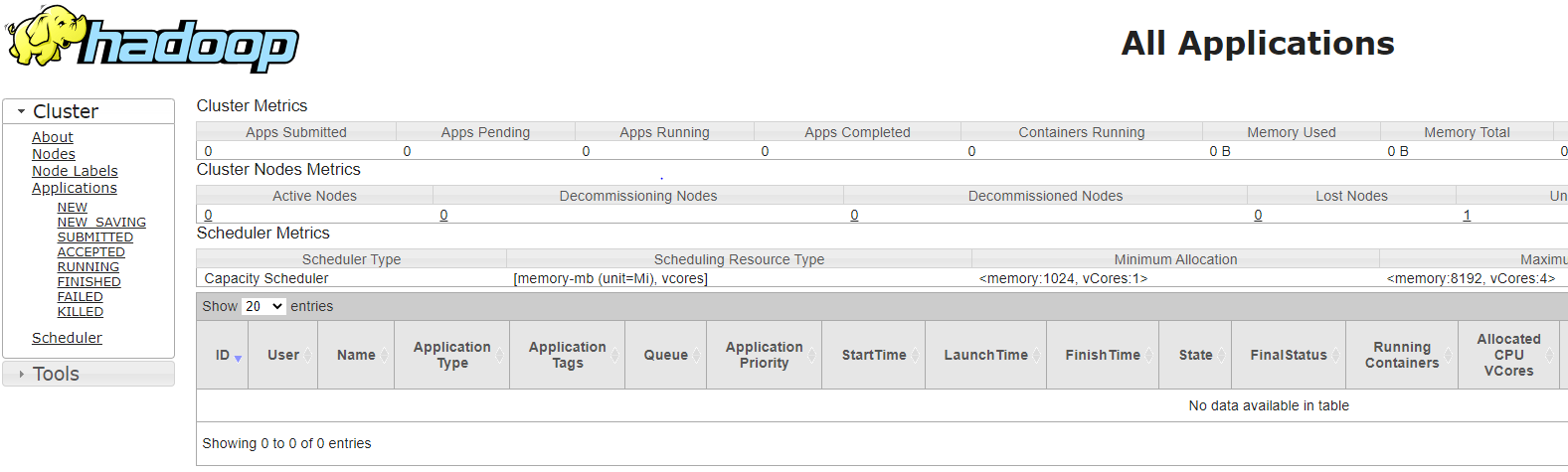
关闭服务
1 | sbin/stop-yarn.sh |
- 检查状态
1
~/hadoop/hadoop-3.3.0$ jps
FAQ
- “etc/hadoop/hadoop-env.sh” E212: Can’t open file for writing
确保导航到正确的Hadoop路径$HADOOP_HOME